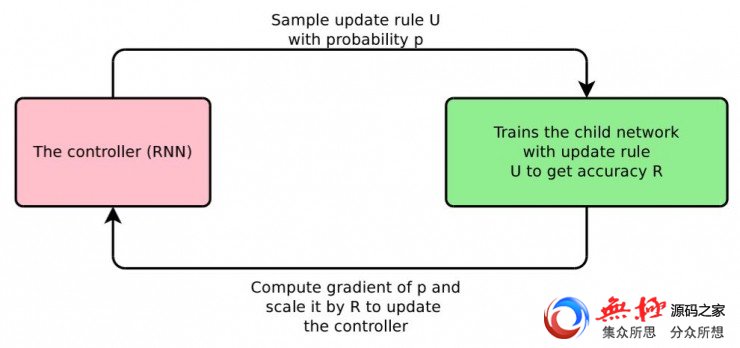
在这篇论文中,谷歌大脑的研究员们讨论了一种方案,它可以自动设计优化方法中的权重更新规则,尤其是对于深度学习架构。这个方案的重点是使用了一个RNN结构的控制器,这个控制器可以给优化器生成权重更新方程。这个RNN结构的控制器是通过强化学习的方式训练的,一个具体的网络结构用它生成的更新规则进行同样次数的训练后,可以把模型准确率最大化。这个过程如下图。
谷歌大脑的研究员们的研究目标是在人们已经熟悉的领域内为神经网络训练找到更好的更新规则。换句话说,他们没打算靠自己重新建立一套全新的更新规则,而是用机器学习算法在现有的更新规则中找到比较好用的。最近也有研究人员提出类似的方法,用模型学习生成更新数值。这里的关键区别是,谷歌大脑的这项研究是为权重更新生成数学形式的方程,而不是直接生成数值。生成一个方程的主要好处是可以轻松地迁移到更大的任务中,而无需为新的优化问题额外训练别的神经网络。而且,虽然他们设计这个方法的目的不是为了优化更新规则的内存占用的,不过还是能够在得到与 Adam 或者 RMSProp 等同的更新规则的情况下占用更少的内存。
雷锋网 AI 科技评论按:谷歌大脑近期放出了一篇论文「Neural Optimizer Search with Reinforcement Learning」(强化学习的神经网络优化器搜索),用强化学习的方法为神经网络(尤其是深度学习)找到最佳的优化算法/权重更新规则。论文并没有重新制造轮子,但也取得了不错的效果,而且也引起了一定的关注。雷锋网 AI 科技评论把论文内容简介如下。
要成功训练一个深度学习模型,选择一个适当的优化方法是非常重要的。虽然随机梯度下降法(SGD)通常可以一上手就发挥出不错的效果,不过 Adam 和 Adagrad 这样更先进的方法可以运行得更快,尤其是在训练非常深的网络时。然而,为深度学习设计优化方法是一件非常困难的事情,因为优化问题的本质是非凸问题。
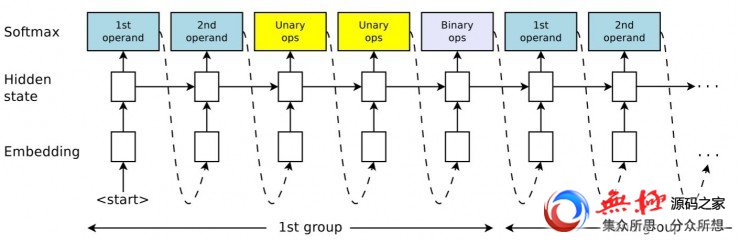
控制器 RNN的总体结构。控制器会迭代选择长度为5的子序列。它首先选择前两个操作数和两个一元函数来应用操作数,然后用一个二进制函数合并两个一元函数的输出。获得的结果b就可以被下一轮子序列选中作为预测,或者成为更新规则。每次的预测都是由一个softmax分类器执行的,最后成为下一轮迭代的输入。原标题:效果超过SGD和Adam,谷歌大脑的「神经网络优化器搜索」自动找到更好的训练优化器
根据论文中的实验结果,在用 CIFAR-10 训练一个小型的卷积网络中,他们的方法比 Adam、RMSProp、带或者不带 Momentum 的 SGD 找到了许多条更好的更新规则,而且这些生成的更新公式中很多都可以轻松地迁移到新的模型架构或者数据集中使用。比如,在小型卷积网络训练中发现的权重更新规则在Wide ResNet 的训练中取得了比 Adam、RMSProp、带或者不带 Momentum 的 SGD 更好的结果。 对于 ImageNet 数据集,他们新找到的更新规则在目前最先进的移动设备级别模型的 top-1 和 top-5 正确率基础上继续提升了最高 0.4%。同样的更新规则在谷歌的神经机器翻译系统上也取得了不错的成果,在WMT 2014 英文到德文的翻译任务中最高能带来0.7BLEU的提升。
神经网络优化器搜索的总体架构训练神经网络很慢、很困难,之前有许多人设计了各种各样的方法。近期的优化方法结合了随机方法和批量方法的特点,比如用mini-batch,跟SGD类似,但是实现了更多的启发式方法来估计二阶对角信息,就和无黑塞方法(Hessian-free)或者L-BFGS类似。这样吸收了两种方法优点的方案通常在实际问题中有更快的收敛速度,比如 Adam 就是一个深度学习中常用的优化器,实现了简单的启发式方法来估计梯度的均值和变化幅度,从而能够在训练中更加稳定地更新权重。
之前的许多权重更新规则都借鉴了凸函数分析中的想法,虽然神经网络中的优化问题是非凸的。近期通过非单调学习速率的启发式方法得到的经验结果表明,在神经网络的训练方面我们仍然知之甚少,还有许多非凸优化的方法可以用来改进训练过程。
论文中的方法受到了近期用强化学习做模型探索的研究的启发,尤其是在神经网络结构搜索上,其中用了一个 RNN 生成神经网络架构的设置文本。除了把这些关键思想用在不同的应用中,论文中的方法还展现出了一种全新的模式,把原有的输入以灵活得多的方法组合起来,从而让搜索新型的优化器变得可能。